
Llama Llama Live! Pittsburgh Official Ticket Source Byham Theater Sat, Jan 14, 2023
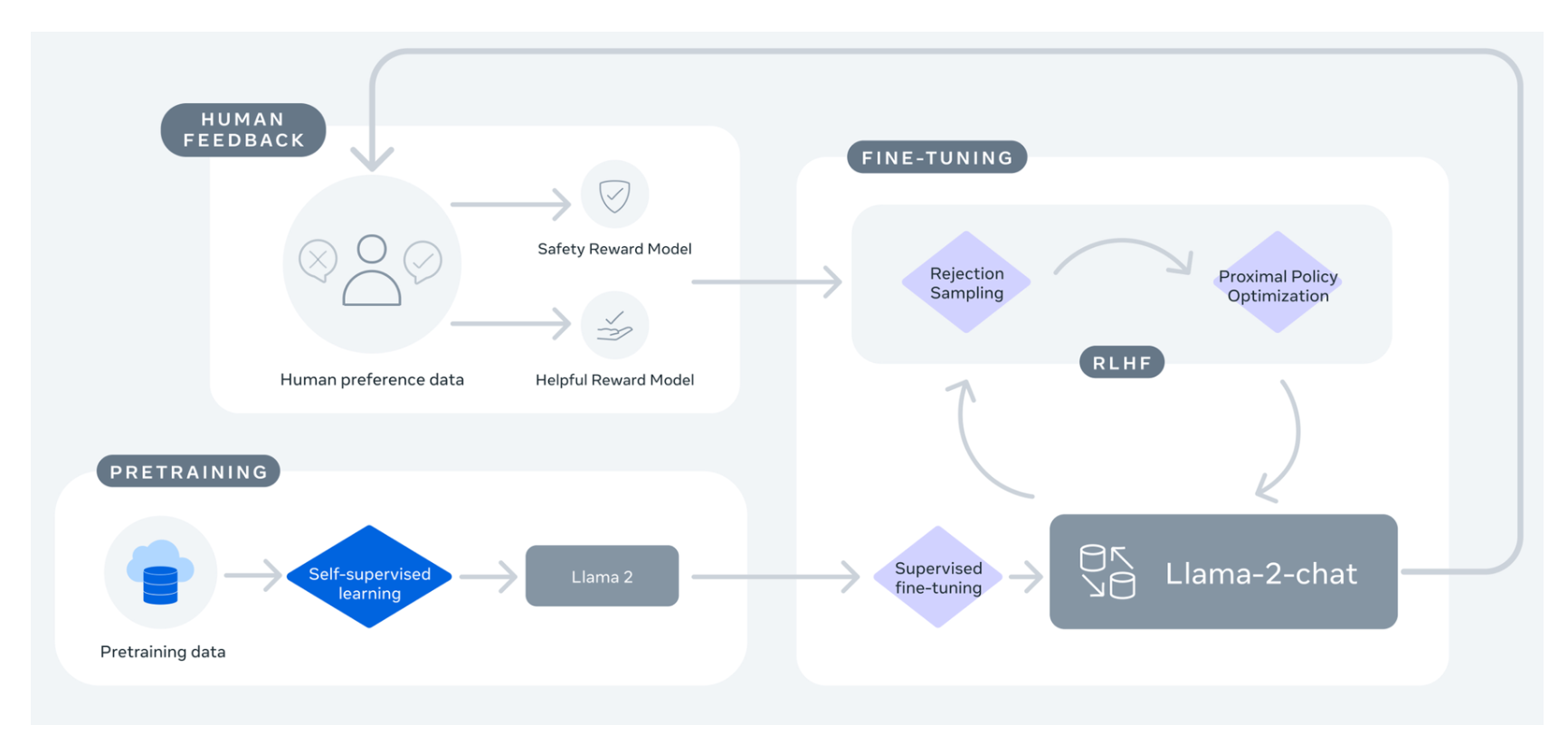
Llama 2-Chat: Fine-Tuning. Llama 2-Chat, optimized for dialogue use cases, is the result of several months of research and iterative applications of alignment techniques, including both instruction tuning and Reinforcement Learning with Human Feedback (RLHF), requiring significant computational and annotation resources. (The paper describes this paper in very detail and verbose, I will just.

Llama paper By DigitalDesignsAndArt TheHungryJPEG
Llama 2 is a family of state-of-the-art open-access large language models released by Meta today, and we're excited to fully support the launch with comprehensive integration in Hugging Face.. This template follows the model's training procedure, as described in the Llama 2 paper. We can use any system_prompt we want, but it's crucial that.

6 Easiest Ways to Get Started with Llama2 Meta’s Open AI Model Be on the Right Side of Change
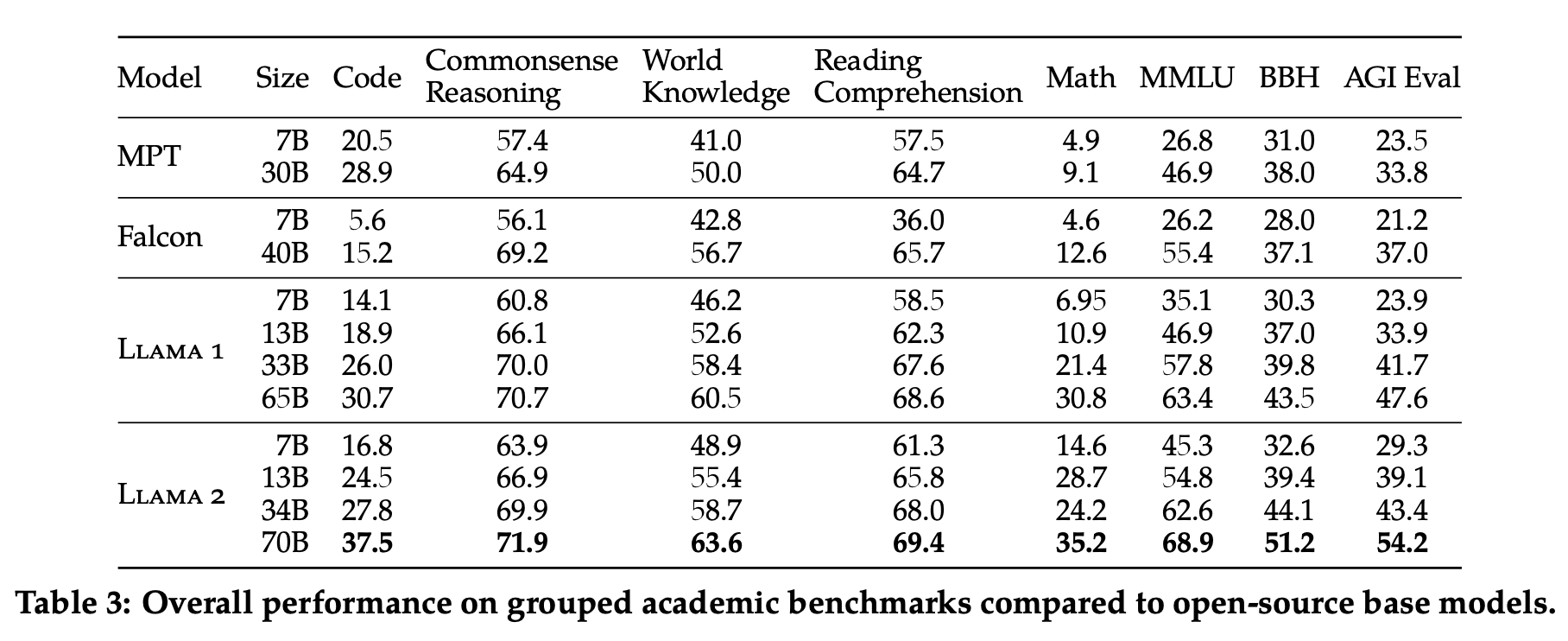
We introduce LLaMA, a collection of foundation language models ranging from 7B to 65B parameters. We train our models on trillions of tokens, and show that it is possible to train state-of-the-art models using publicly available datasets exclusively, without resorting to proprietary and inaccessible datasets. In particular, LLaMA-13B outperforms GPT-3 (175B) on most benchmarks, and LLaMA-65B.

Llama Paper Flowers Llama Party Decorations Llama Etsy Paper flower arrangements, Paper
About Large language model Llama 2: open source, free for research and commercial use We're unlocking the power of these large language models. Our latest version of Llama - Llama 2 - is now accessible to individuals, creators, researchers, and businesses so they can experiment, innovate, and scale their ideas responsibly.

Meta and Microsoft Introduce Llama 2 Language Model for AI • iPhone in Canada Blog
arxiv:2307.09288 Llama 2: Open Foundation and Fine-Tuned Chat Models Published on Jul 18, 2023 · Featured in Daily Papers on Jul 19, 2023 Authors: Hugo Touvron , Louis Martin , Kevin Stone , Peter Albert , Amjad Almahairi , Yasmine Babaei , Nikolay Bashlykov , Soumya Batra , Prajjwal Bhargava , Shruti Bhosale , Dan Bikel , Lukas Blecher ,
Meta announces Llama 2; "open sources" it for commercial use — AI Alignment Forum
The LLaMA-2 paper describes the architecture in good detail to help data scientists recreate & fine-tune the models. (unlike OpenAI papers where you have to deduce it indirectly). It's trained on.

Llama Pair White Free Stock Photo Public Domain Pictures
Papers Explained 60: Llama 2 Ritvik Rastogi · Follow Published in DAIR.AI · 6 min read · Oct 9, 2023 -- Llama 2 is a collection of pretrained and fine-tuned large language models (LLMs).

Llama Llama Llama Or is it llama llama duck? Ed Schipul Flickr
Melanie Kambadur Aurelien Rodriguez Guillaume WenzekFrancisco Guzmán In this work, we develop and release Llama 2, a collection of pretrained and fine-tuned large language models (LLMs) ranging in scale from 7 billion to.

Hello! I'm glad you liked it! Of course it is fine if you translate and share it with the link
Published on 08/23/23 Updated on 10/11/23 Llama 1 vs. Llama 2: Meta's Genius Breakthrough in AI Architecture | Research Paper Breakdown First thing's first: We actually broke down the Llama-2 paper in the video above. In it, we turn seventy-eight pages of reading into fewer than fifteen minutes of watching.
Meta, 상업적 사용이 가능한 오픈소스 언어 모델 LLaMA 2 공개 (7B, 13B, 70B / 4k context) 읽을거리&정보공유 파이토치 한국 사용자 모임
This work develops and releases Llama 2, a collection of pretrained and fine-tuned large language models (LLMs) ranging in scale from 7 billion to 70 billion parameters, which may be a suitable substitute for closed-source models. In this work, we develop and release Llama 2, a collection of pretrained and fine-tuned large language models (LLMs) ranging in scale from 7 billion to 70 billion.

llama icon Clip Art Library
In this work, we develop and release Llama 2, a collection of pretrained and fine-tuned large language models (LLMs) ranging in scale from 7 billion to 70 billion parameters.. Additionally, this paper contributes a thorough description of our fine-tuning methodology and approach to improving LLM safety. We hope that this openness will enable.
Llama 2 Paper
We have a broad range of supporters around the world who believe in our open approach to today's AI — companies that have given early feedback and are excited to build with Llama 2, cloud providers that will include the model as part of their offering to customers, researchers committed to doing research with the model, and people across tech, academia, and policy who see the benefits of.

llama 2 paper ChatGPT für Unternehmen
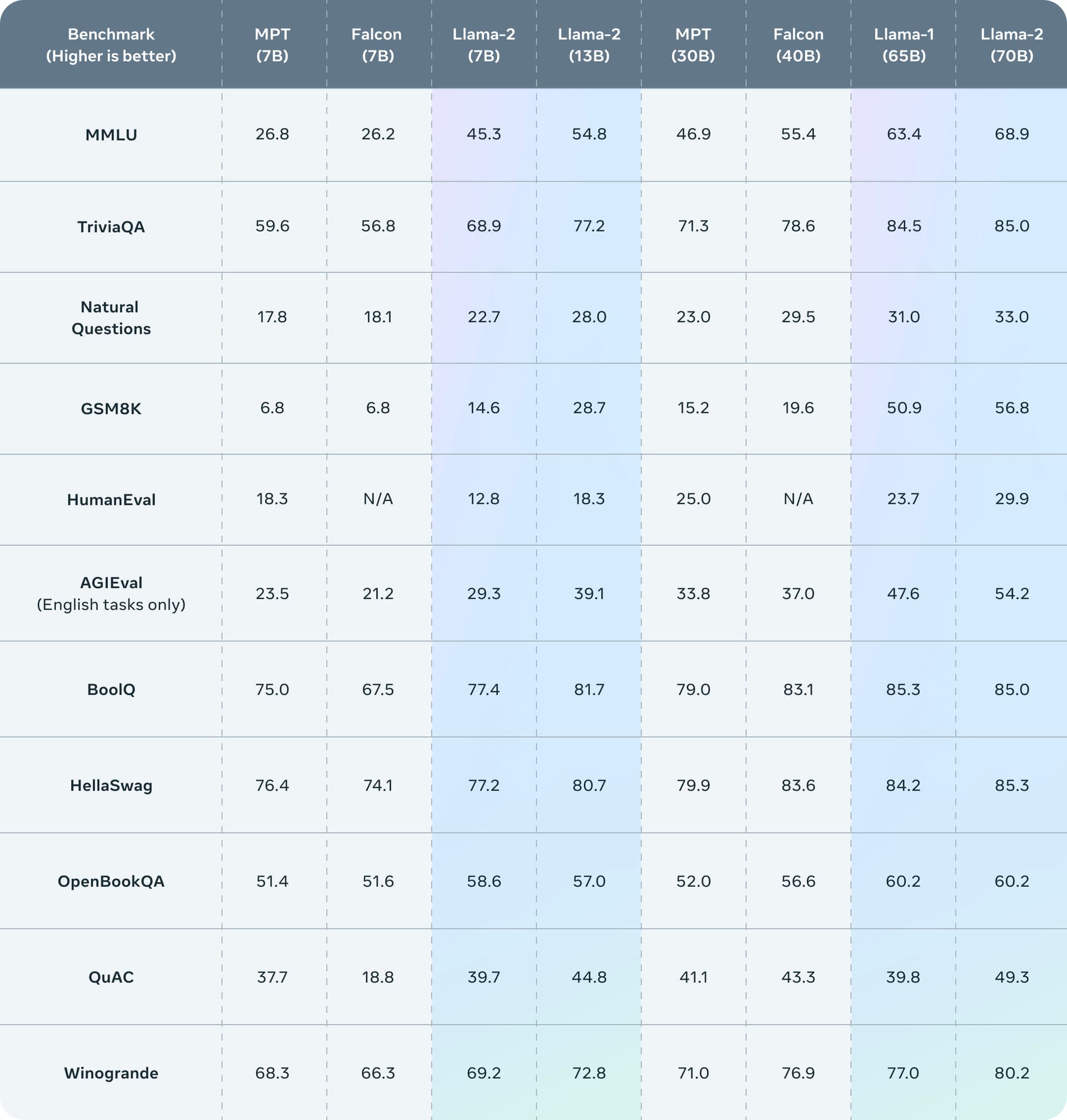
As reported in the appendix of the LLaMA 2 paper, the primary architectural differences from the original model are increased context length and grouped-query attention (GQA). The context window was doubled in size, from 2048 to 4096 tokens. This longer process window enables the model to produce and process far more information.

llama clipart transparent background Clip Art Library
We release Code Llama, a family of large language models for code based on Llama 2 providing state-of-the-art performance among open models, infilling capabilities, support for large input contexts, and zero-shot instruction following ability for programming tasks.

What's new in Llama 2 & how to run it locally AGI Sphere
Llama 2 is a large language AI model comprising a collection of models capable of generating text and code in response to prompts.. Open Foundation and Fine-Tuned Chat Models paper ; Meta's Llama 2 webpage ; Meta's Llama 2 Model Card webpage ; Model Architecture: Architecture Type: Transformer Network Architecture: Llama 2 Model version: N/A.

Llama 2 Explained Training, Performance and Results
Download PDF Abstract: In this work, we develop and release Llama 2, a collection of pretrained and fine-tuned large language models (LLMs) ranging in scale from 7 billion to 70 billion parameters. Our fine-tuned LLMs, called Llama 2-Chat, are optimized for dialogue use cases. Our models outperform open-source chat models on most benchmarks we tested, and based on our human evaluations for.